The two paradigms of Artificial Intelligence: OpenAI's Approach to Building Thinking Machines
- Megi Kavtaradze
- Nov 8, 2024
- 7 min read


Member of Technical Staff / Research Scientist at OpenAI
In a recent presentation at the Berkeley Haas AI Summit, OpenAI’s Jason Wei highlighted two distinct but complementary strategies that are propelling artificial intelligence forward. Wei’s insights shed light on the current blueprint for creating AI that can do more than follow simple instructions – the goal is to build systems that can reason, adapt, and even tackle problems much like a human would.
How does OpenAI's dual-paradigm strategy – combining massive-scale pattern recognition with chain-of-thought reasoning – shape its approach to building more capable AI systems?
Path 1: Scaling AI’s Predictive Powers – From Basic to Brilliant
Just a few years ago, AI could barely write a coherent paragraph. But today, language models are composing essays, solving math problems, and programming at levels that would have been unimaginable back in 2019. What drove this rapid improvement?
It all starts with something called scaling. Scaling is about making the model larger – increasing the amount of data it processes, boosting its computing power, and building a more complex network of “neurons.” This approach has proven shockingly effective: as AI systems grow in size and complexity, they consistently improve across a wide range of tasks.
Why does this happen? A big part of the answer lies in what AI researchers call next-word prediction. Essentially, these AI models learn to predict the next word in a sentence by studying billions of different sentences and contexts. This might sound simple, but it’s incredibly powerful because, by learning to predict words, the model also picks up skills in grammar, general knowledge, reasoning, and even spatial awareness. So, the more words and sentences the model sees, the more it understands – not just language but the structure of knowledge itself.
Think of it like training someone to be an expert in hundreds of different games all at once. It’s an intense learning experience, and it helps the model become broadly capable, handling many different tasks without needing a separate, specialized program for each one.
Why Scaling Laws Matter: Unlocking New Capabilities
When researchers talk about scaling laws, they’re referring to the observation that as models become larger (more data, more compute, more parameters), their performance improves in a reliable, predictable way. But scaling doesn’t just make the model better at simple tasks. As models grow, they start to develop unexpected abilities.
For example, while a smaller model might learn to add two numbers, a larger model might also learn how to translate languages. These unexpected, “emergent” abilities are a fascinating result of scaling – they appear to arise naturally as the model expands. What’s exciting about these capabilities is that they don’t require special programming; the AI simply learns them as it “sees” more data. This has changed the game for AI research, allowing us to push boundaries without re-inventing the model’s core structure.
Path 2: Chain-of-Thought – Teaching AI to Think, Step by Step
Despite all the progress made through scaling, there’s a limit to what prediction alone can achieve. Some tasks require more than quick responses – they demand careful, step-by-step reasoning. For instance, you wouldn’t solve a tricky math problem in a single step. Instead, you would break it down into smaller parts, solving each in turn.
This is where the chain-of-thought (CoT) approach comes in. Rather than making the model faster or more predictive, CoT focuses on teaching AI to think through problems systematically, almost as if it were planning each move in a chess game. By training models to work through steps, researchers enable AI to tackle complex problems that would otherwise be too challenging.
To understand this better, think of two types of thinking: one is fast and intuitive (like recognizing a friend’s face), and the other is slow and deliberate (like figuring out how to solve a puzzle). Traditional AI models have mostly used the fast type of thinking, providing answers based on accumulated knowledge. But with CoT, AI can take a more methodical approach, working through tasks that require careful reasoning and multiple steps. This shift is critical for making AI capable of handling more nuanced tasks.
The Importance of Verification: Learning Through Trial and Error
A significant insight that emerged from Wei’s presentation is something called asymmetry of verification. This concept refers to the fact that some problems are easier to verify than to solve. Take crossword puzzles: it’s easier to check if an answer is correct than it is to create the entire puzzle. For AI, this means it can try various solutions, verify which ones work, and refine its approach based on what it learns.
By letting AI test out different methods and verify the correct answer, researchers are training models to become more than simple pattern-matching machines. This process is more akin to how humans learn: we don’t just memorize answers; we figure out why something works. This verification-based learning could make future AI systems more resilient and adaptive, capable of handling challenges with far less trial and error.
Why the Shift in Research Culture Matters
The move from specialized AI models to more generalized, broadly capable systems has transformed AI research. Five years ago, AI projects often involved small teams working on specific, isolated tasks. Today, achieving general AI capability requires massive collaboration and cutting-edge infrastructure. Research has shifted from excelling at individual benchmarks (like beating humans at chess) to building models that are competent across a wide range of fields.
Instead of asking, “How well can we perform this single task?” the new question is, “How broadly capable can this model become?” This shift represents a fundamental change in how researchers view AI’s potential, moving from narrowly focused programs to highly adaptable, multi-tasking systems.
What’s Next? The Convergence of Scaling and Chain-of-Thought
So, where do these two paths lead? The future of AI may not lie in choosing between prediction and reasoning, but in combining them. By merging the intuitive pattern recognition of scaled models with the methodical reasoning of chain-of-thought, researchers could create systems that excel in both speed and depth. Imagine an AI that can not only write essays and solve math problems but also conduct original scientific research, make medical discoveries, or even tackle the ethical challenges of AI safety.
The implications are enormous. If these paths converge, AI could transform from a powerful tool into a true intellectual partner, capable of reasoning, understanding context, and tackling complex issues across disciplines. But perhaps even more intriguingly, this development could help us better understand human intelligence. As AI becomes more capable of reasoning, we gain new insights into our own thinking processes and what it means to “understand.”
Conclusion: Comparing Chain-of-Thought (CoT) and Next-Word Prediction, and What’s Next for AI
As we look to the future, it’s helpful to directly compare the two paths OpenAI has pursued in advancing AI – Next-Word Prediction and Chain-of-Thought (CoT) prompting. Both have unique strengths and limitations, and understanding these distinctions sheds light on where AI development may be headed next.

Examples in Practice
Next-Word Prediction: Consider a sentence like, “The capital of France is ___.” GPT-3 would handle this with ease by predicting the word "Paris" based on vast exposure to general knowledge during training. This approach is fast and efficient, ideal for tasks where the correct answer often involves common or factual data.
Chain-of-Thought Prompting: Now take a more complex question, like, “What is the square of ((8-2)*3+4)^3 / 8?” For a question like this, GPT-4 with CoT prompting would work step-by-step through the math, calculating intermediate results and arriving at the final answer. This is a slower, more resource-intensive process but necessary for handling nuanced problems that require layered reasoning.
Evolution of GPT Models: GPT-3 to GPT-3.5 to Chain-of-Thought AI
The journey from GPT-3 to GPT-3.5 marked a shift in AI’s predictive capabilities. GPT-3.5 demonstrated a broader knowledge base and improved language understanding due to its scaled data and compute power. However, it still operated primarily on next-word prediction, so its ability to tackle multi-step or complex tasks was limited.
With GPT-4, OpenAI introduced chain-of-thought prompting, bringing reasoning to a new level. This allowed GPT-4 to break down complex problems into steps, making it far more capable in handling logical sequences and challenging queries. However, CoT requires significant computational power, and it’s a trade-off between model efficiency and depth of reasoning.
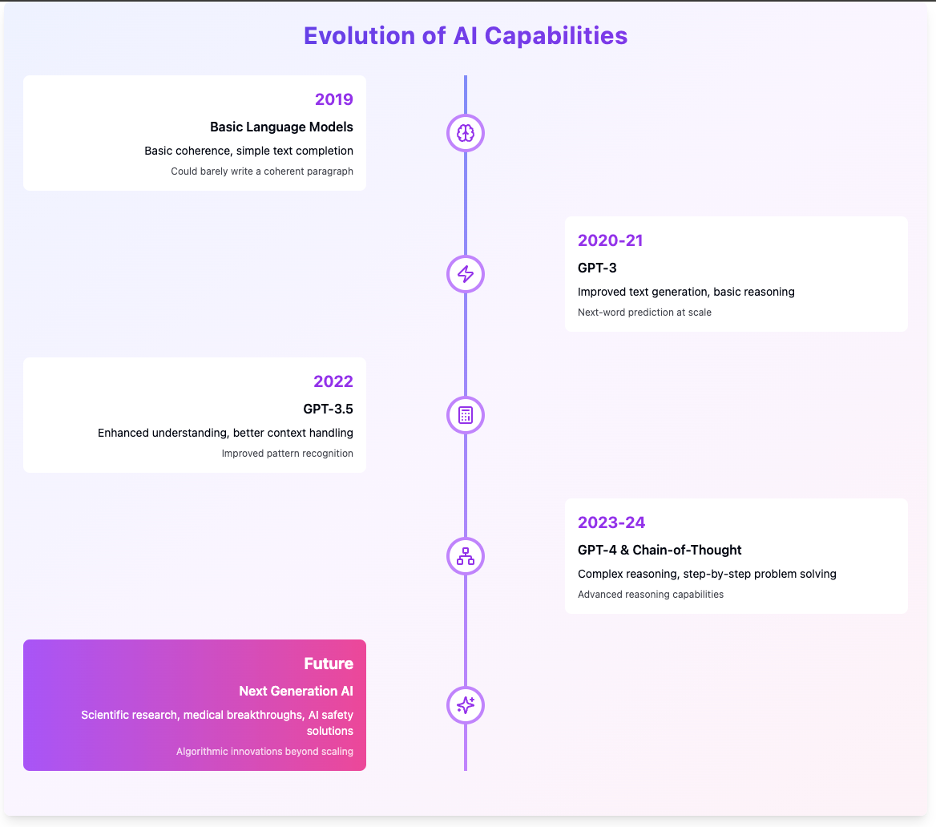
My Perspective: What Will It Take for GPT Models to Advance Even Further?
The next leaps in AI will likely require more than just adding data or making the models larger. Simply scaling up has diminishing returns – every additional unit of data or compute power brings a smaller performance boost. Instead, to push models like GPT Preview to new heights, algorithmic innovations will be essential. Here’s why:
Marginal Gains from Data Saturation: As models grow, they’ve already consumed vast amounts of data. Beyond a certain point, adding more data provides diminishing returns, particularly when much of the additional data is redundant or not optimally relevant. Future gains will come from learning to extract deeper insights from existing data, not just increasing quantity.
Advanced Algorithms for Better Value: AI models need smarter, more efficient algorithms that help them understand and synthesize information. Future models could benefit from techniques that enable them to learn contextually rather than just scaling up their data processing. For instance, rather than having the model memorize millions of unique examples, new algorithms could teach it to generalize patterns and relationships within the data better.
Adaptive Compute and Dynamic Processing: Innovations in how compute resources are allocated will be crucial. Tasks should dynamically adapt to different levels of compute based on complexity. For instance, a model could automatically switch to a deeper, CoT-based reasoning path only when it identifies that a question requires it, saving resources on simpler tasks.
In summary, I believe that the future of AI won't hinge solely on creating larger models or even on ensuring exceptional data quality. While data quality is undeniably crucial, especially when it’s curated by top-tier professionals rather than general human-in-the-loop annotators, there are limits to what even the highest quality data can achieve. Beyond a certain threshold, merely improving data quality will bring diminishing returns, and we’ll reach a point where more refined data alone won’t propel AI capabilities forward.
To truly push the boundaries, we’ll need innovative algorithmic advancements that allow models to extract deeper insights, learn more flexibly, and adapt more effectively to complex tasks. These advancements will be essential in transforming AI from surface-level pattern recognition into systems capable of genuine problem-solving and nuanced reasoning. This shift towards algorithmic innovation will be the key to unlocking the next generation of AI capabilities, moving beyond just “bigger and better” models and into a new era of smart, adaptive artificial intelligence.

Author:
@Megi Kavtaradze
@Product Manager, Technical
@Berkeley Haas MBA 25'
@Ex-Adobe PMM Intern



Comments